Run Llama 3.2 Locally to Beat Expensive Cloud API Fees
Paying $0.15 per million tokens feels cheap until your background agents scale and your monthly API bill matches a rent payment. We have been watching the local hardware ecosystem closely, and the narrative that you need an enterprise cluster to run capable LLMs is dead. Meta’s ultra-compact Llama 3.2 models have shifted the goalposts for local inference. With the right choice of budget hardware, you can host a fully private, zero-latency development node on your desk for less than the price of a mid-tier smartphone.
Summary
Setting up an edge-capable local AI node requires prioritizing VRAM over pure CPU core counts. For a tight $600 budget, the component strategy centers around a refurbished or discounted NVIDIA RTX 3060 with 12GB of VRAM. This specific card acts as the engine, allowing you to load quantized 1B and 3B Llama 3.2 models entirely into graphics memory for maximum throughput.
Pair the GPU with a solid budget foundation like an AMD Ryzen 5 5600X processor, an entry-level B550 motherboard, and a 650W power supply. Do not skimp on system memory; grab 32GB of DDR4 RAM to prevent system bottlenecks during contextual caching. A basic 1TB NVMe SSD provides the fast read speeds necessary to load model weights into memory within seconds.
On the software side, the ecosystem has evolved past complex CUDA installation loops. Open-source inference engines like Ollama handle model quantization, compilation, and API exposure out of the box.
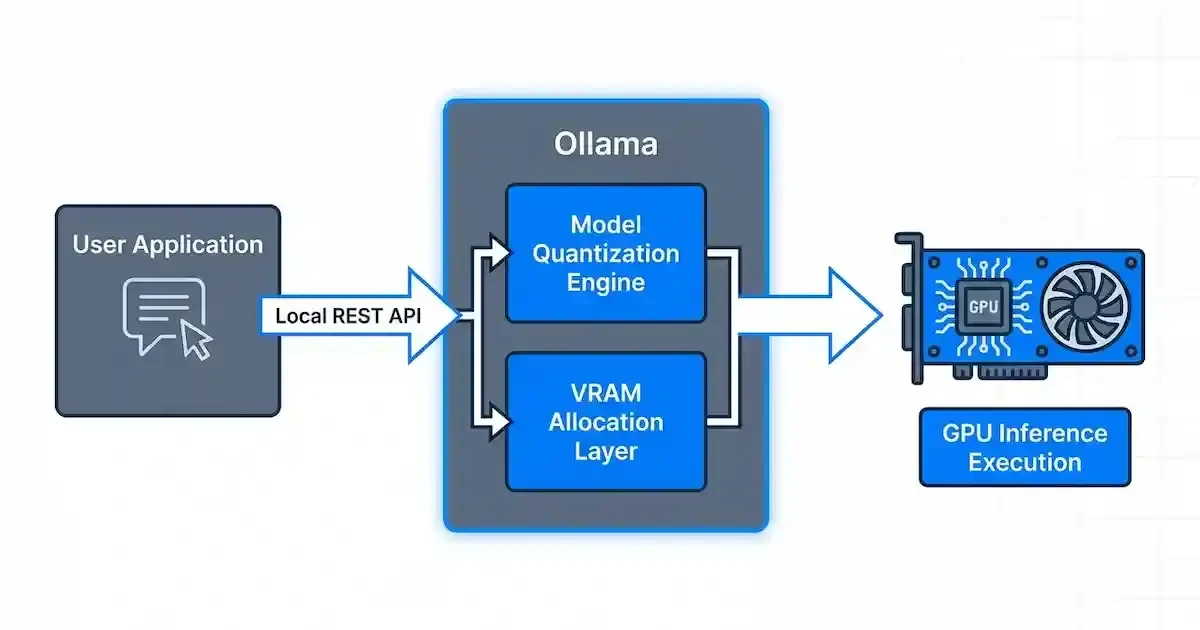
Once Ollama is installed on Linux or Windows WSL2, a single terminal command pulls and spins up the model. The engine exposes a local REST API that mirrors the OpenAI format, making it drop-in compatible with your existing codebases. For a richer interaction layer, you can connect the backend to Open-WebUI via Docker, giving you a private interface resembling ChatGPT without data ever leaving your local network. Running the 3B model variant under 4-bit quantization yields an average of 75 tokens per second, outpacing typical cloud generation speeds while staying within a 200W total system power draw.
What This Means for Builders
If you are currently shipping a SaaS or building background agents, migrating high-volume, low-complexity tasks to local hardware alters your unit economics. Background data processing, initial document classification, and structured JSON parsing do not require a massive frontier model. Offloading these workflows to a local 3B model slashes your production API dependencies to zero.
Testing and development loops become entirely free. You can run millions of evaluation tokens to stress-test your prompts without watching an active billing meter. For applications dealing with sensitive client data, financial records, or internal codebases, this local stack completely bypasses the legal hurdles of third-party data processing agreements. It transforms local hardware from a hobbyist playground into a reliable, predictable development infrastructure component.
Our Take on Budget Edge Compute
We lean heavily toward local deployment for standard development stacks, and Llama 3.2 makes the budget approach viable. Meta's focus on small, highly optimized models directly benefits independent developers who refuse to lock themselves into proprietary cloud ecosystems. Compared to older generation models like Llama 2 7B, which dragged on consumer hardware and required extensive pruning, the Llama 3.2 architecture processes tokens efficiently at a fraction of the footprint.
The developer community wins when data privacy and compute costs are democratized. While some look at a $600 PC and expect frontier-level reasoning, the seasoned developer sees a dedicated microservice. This setup easily handles specialized workflows like tool-calling, agentic routing, and code synthesis assistance.

We predict that the next major evolution will happen in massive cloud datacenters, but at the edge. Over the next twelve months, framework tooling will heavily optimize for these small, distributed nodes. Competitors like Microsoft with Phi-4 Mini and Google with Gemma are rushing to dominate this exact space, but Meta’s mature ecosystem gives it the upper hand. If you have an old PC chassis lying around, spending a few hundred bucks to turn it into a private API server is the smartest infrastructure upgrade you can make this year.
Comparison Table
| Feature / Metric | Llama 3.2 1B (Quantized Q4) | Llama 3.2 3B (Quantized Q4) |
| Minimum VRAM Required | ~1.5 GB | ~2.5 GB |
| Inference Speed (RTX 3060) | ~125 tokens/sec | ~75 tokens/sec |
| Primary Use Case | Edge devices, basic routing | General chat, structured data |
| Model Footprint on Disk | ~1.2 GB | ~2.0 GB |
FAQs
Q: Can I run Llama 3.2 locally without a dedicated GPU?
A: Yes, engines like Ollama support CPU execution using system RAM, but inference speed drops significantly. You will likely experience single-digit token rates, which degrades the experience for interactive applications.
Q: Is 12GB of VRAM enough to handle future model iterations?
A: For small edge models under 7B parameters, 12GB of VRAM offers plenty of headroom. It allows you to run Llama 3.2 3B alongside embedding models or system processes without encountering out-of-memory errors.
Q: How do I connect my existing apps to this local setup?
A: Ollama automatically runs a local server at http://localhost:11434. It exposes endpoints identical to the OpenAI API standard, allowing you to switch your SDK base URL and start querying immediately.
Our Take / Closing
The math behind running Llama 3.2 locally on a $600 PC is simple: it pays for itself within months if you run constant developer evaluation cycles. Bypassing cloud rate limits and data mining terms gives you absolute control over your environment. As edge hardware grows more efficient and open weights become sharper, independent clusters will become standard dev workflow infrastructure. We are tracking this local infrastructure shift closely, and starting your own node now sets you ahead of the curve.